
Bedrock Uncovered: Features and Insights
A Hands-On Review of Bedrock's Capabilities and Future Potential in Real-Time Solutions

TL;DR: Tested AWS Bedrock's capabilities, appreciating its user-friendly model deployment while noting areas for future enhancements. A promising tool with room to grow.
I had the opportunity to experiment with AWS Bedrock over the weekend, and I want to share some insights on its practicality and feasibility for building real-time solutions.
(Note: It's important to recognise that Bedrock is still in its early stages, with more features expected in the future.)
Launching Basic Fine-Tuned Models
With Bedrock, launching foundational models like Llama 2, Cohere, and Claude is incredibly straightforward. Unlike SageMaker, there's no need to set up endpoints or a notebook to run a fine-tuned model. Bedrock offers on-demand APIs for this purpose. I ran a llama-2-70b and an SDXL 1.0 image generator effortlessly, without the hassle of setting up an instance or an endpoint.
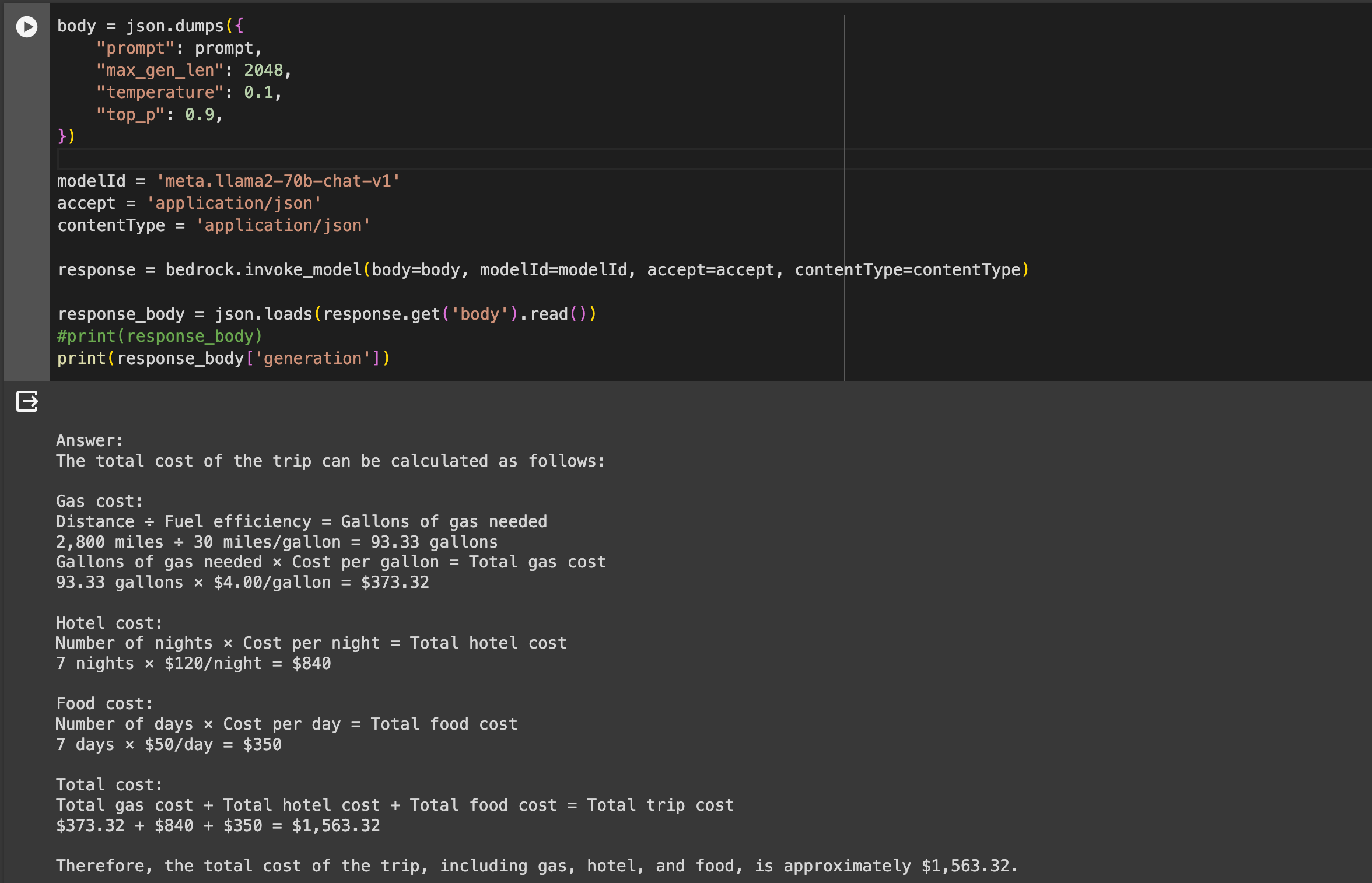
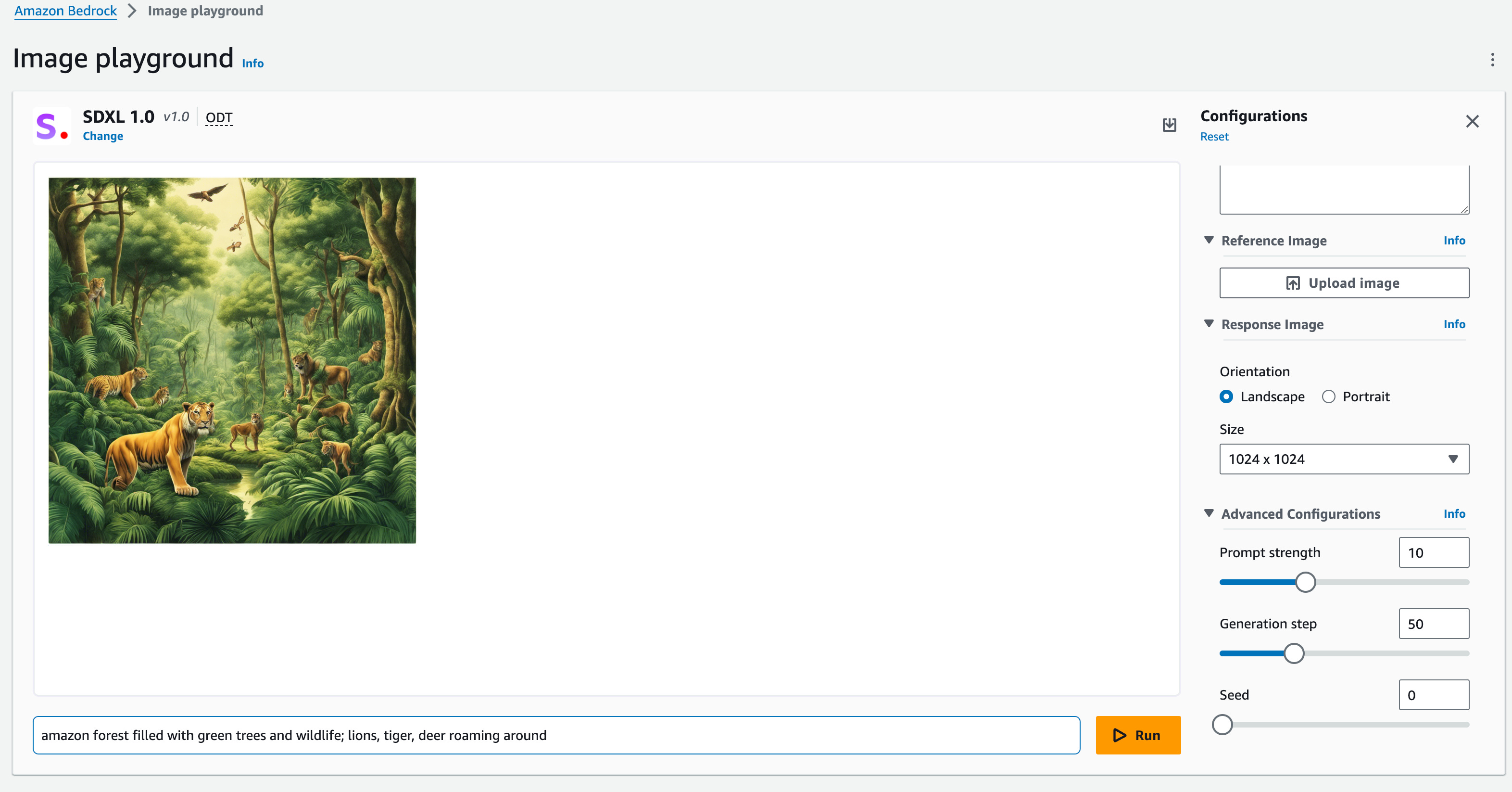
However, with the continually growing number of open-source LLMs, Bedrock currently doesn’t support BYOM (Bring Your Own Models). In this aspect, SageMaker offers greater flexibility in loading and running your own model at the moment.
RAG Setup
For those unfamiliar with RAG, further information can be found here.
Bedrock simplifies the setup for Retrieval-Augmented Generation (RAG). It can even create its own vector database, which I managed to set up in just a few minutes!
The limitation is that it currently supports only text documents, PDFs, HTML, markdown, etc., and is restricted to Anthropic models. There is, however, the flexibility to configure your own vector database.
Agents
In Bedrock, agent setup is limited to Anthropic models and Amazon Titan Express, AWS's own foundational model. For those seeking more flexibility, setting up one's own infrastructure might be necessary at this stage.
Custom Models
The prospect of working with custom models in Bedrock was intriguing, but it requires purchasing a provisioned instance for either 1 or 6 months to fine-tune a model (might be too much on your pocket if you want to try a simple fine-tuning job) . In this scenario, SageMaker appears to be a better option.
However, Bedrock does offer the ability to pre-train a model on a specific domain, which is quite impressive, although it still necessitates a provisioned instance.
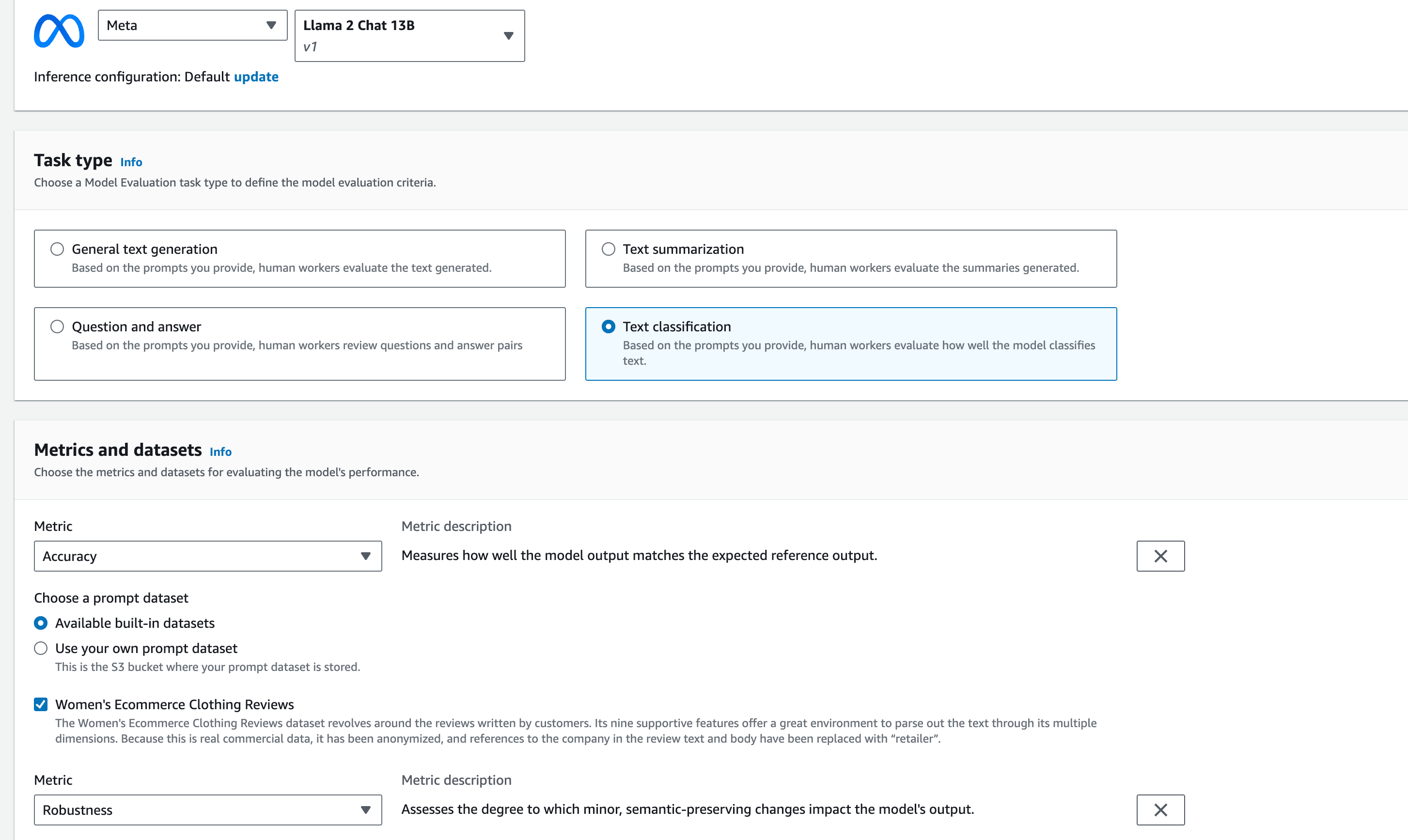
Model Evaluation
This feature is particularly exciting. Although I haven't explored it thoroughly, AWS provides a robust framework for selecting one of its models, assigning a task, and determining the evaluation criteria. The results are later stored in an S3 file.
Verdict
While Bedrock is still in the nascent stages of development, it brings to the table a host of features that can save significant time. However, it does lack the flexibility a data scientist might seek. I'm hopeful that future updates will enhance its capabilities further, such as the ability to load Hugging Face models and choose custom embeddings.
Have you had a chance to experiment with AWS Bedrock, or are you considering it for your projects? Let me know in the comments below! I’d love to hear about your experiences or expectations.
Enjoying the insights? Don't miss out on future posts!
To know more about AWS Bedrock, check out AWS re:Invent 2023 below!